PDP, 3
범위 규칙 (앵커)
저자 : Tobias Goerke & Magdalena Lang
이 장은 현재이 웹 버전에서만 사용할 수 있습니다.
전자 책과 인쇄물이 따라옵니다.
Anchors는 예측을 충분히 "고정"하는 결정 규칙을 찾아 모든 블랙 박스 분류 모델의 개별 예측을 설명합니다.
규칙은 다른 특성 값의 변경이 예측에 영향을주지 않는 경우 예측을 고정합니다.
Anchors는 그래프 검색 알고리즘과 함께 강화 학습 기술을 활용하여 모델 호출 수 (따라서 필요한 런타임)를 최소로 줄이면서도 로컬 최적화에서 복구 할 수 있습니다.
Ribeiro, Singh 및 Guestrin 은 LIME 알고리즘 을 도입 한 동일한 연구원 인 2018 년 40 년에 알고리즘을 제안했습니다 .
전임자와 마찬가지로 anchors 접근 방식은 섭동 기반 전략을 배포하여 블랙 박스 기계 학습 모델의 예측에 대한 로컬 설명 을 생성 합니다.
그러나 LIME에서 사용하는 대리 모델 대신 결과 설명은 앵커 라고하는 이해하기 쉬운 IF-THEN 규칙 으로 표현됩니다 .
이러한 규칙은 범위 가 지정 되어 있으므로 재사용 가능합니다.:
앵커에는 적용 할 수있는 다른, 아마도 보이지 않을 수있는 경우를 정확하게 나타내는 커버리지 개념이 포함됩니다.
앵커 찾기에는 강화 학습 분야에서 비롯된 탐색 또는 다중 슬롯 머신 문제가 포함됩니다.
이를 위해 설명되는 모든 인스턴스에 대해 이웃 또는 섭동이 생성되고 평가됩니다.
이렇게하면 접근 방식이 블랙 박스의 구조와 내부 매개 변수를 무시하여 관찰되지 않고 변경되지 않은 상태로 유지 될 수 있습니다.
따라서 알고리즘은 모델에 구애받지 않으므로 모든 모델 클래스에 적용 할 수 있습니다 .
논문에서 저자는 두 알고리즘을 비교하고 결과를 도출하기 위해 인스턴스의 이웃을 얼마나 다르게 참조하는지 시각화합니다.
이를 위해 다음 그림은 두 개의 예시적인 인스턴스를 사용하여 복잡한 이진 분류기 ( - 또는 + 예측 )를 로컬로 설명하는 LIME 및 앵커를 모두 보여줍니다 .
LIME의 결과는 LIME가 섭동 공간 주어지면 모델에 가장 근접한 선형 결정 경계 만 학습하므로 얼마나 충실한지를 나타내지 않습니다.
D. 동일한 섭동 공간이 주어지면 앵커 접근법은 적용 범위가 모델의 동작에 맞게 조정되고 경계를 명확하게 표현하는 설명을 구성합니다.
따라서 그들은 설계 상 충실하며 어떤 경우에 유효한지 정확하게 명시합니다.
이 속성은 앵커를 특히 직관적이고 이해하기 쉽게 만듭니다.
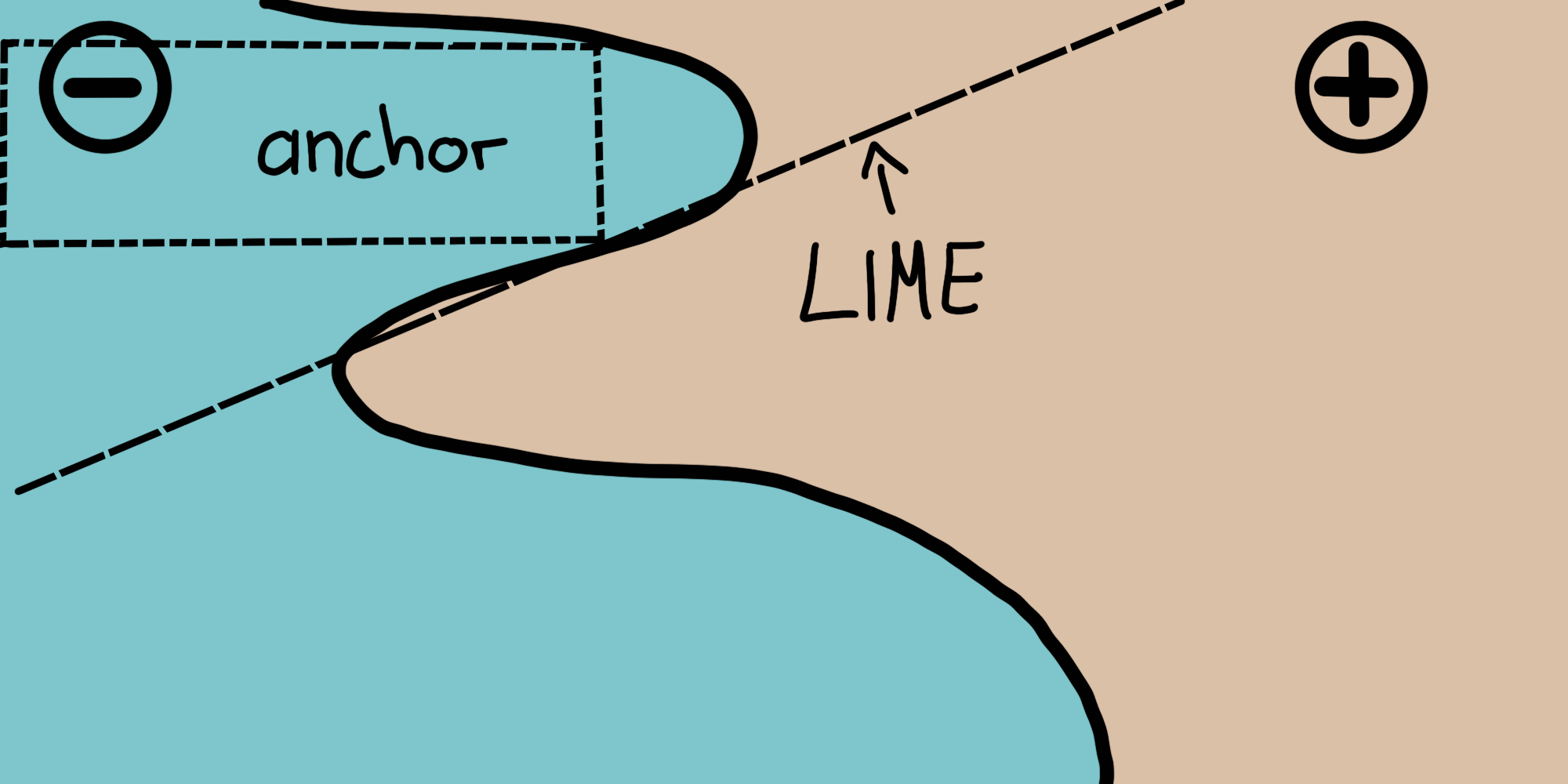
그림 5.37 : 라임 대 앵커-장난감 시각화. Ribeiro, Singh 및 Guestrin의 그림 (2018).
앞서 언급했듯이 알고리즘의 결과 또는 설명은 앵커라고하는 규칙의 형태로 제공됩니다.
다음의 간단한 예는 이러한 앵커를 보여줍니다.
예를 들어 승객이 타이타닉 재난에서 살아남는지 여부를 예측하는 이변 량 블랙 박스 모델이 있다고 가정합니다.
이제 우리는 모델이 특정 개인에 대해 생존한다고 예측하는 이유 를 알고 싶습니다 .
앵커 알고리즘은 아래와 같은 결과 설명을 제공합니다.
한 명의 모범적 인 개인과 모델의 예측특색값
| 나이 | 20 |
| 섹스 | 여자 |
| 수업 | 먼저 |
| 표 가격 | 300 달러 |
| 더 많은 속성 | ... |
| 생존 | 진실 |
해당 앵커 설명은 다음과 같습니다.
IF SEX = female
AND Class = first
THEN 예측 Survived = true
정밀도 97%
및 적용 범위15%
이 예제는 앵커가 모델의 예측 및 기본 추론에 대한 필수 통찰력을 제공하는 방법을 보여줍니다.
결과는 모델이 어떤 속성을 고려했는지 보여줍니다.
이 경우에는 여성의 성별과 일류입니다.
정확성을 위해 가장 중요한 인간은이 규칙을 사용하여 모델의 동작을 검증 할 수 있습니다.
앵커는 또한 섭동 공간 인스턴스의 15 %에 적용된다는 것을 알려줍니다.
이 경우 설명은 97 % 정확합니다. 즉, 표시된 술어가 예측 된 결과에 대해 거의 전적으로 책임이 있습니다.
앵커 는 공식적으로 다음과 같이 정의됩니다.A
EDx(z|A)[1f(x)=f(z)]≥τ,A(x)=1
여기서 :
- x 는 설명되는 인스턴스를 나타냅니다 (예 : 테이블 형식 데이터 세트의 한 행).
- A 되도록 조건의 세트, 즉, 생성 된 규칙 또는 앵커이다 할 경우에 정의 된 모든 기능 술어 에 대응 ' 의 기능 값.A(x)=1Ax
- f 는 설명 할 분류 모델 (예 : 인공 신경망 모델)을 나타냅니다. 및 그 섭동에 대한 레이블을 예측하기 위해 쿼리 할 수 있습니다 .x
- Dx(⋅|A) 는 와 일치하는 의 이웃 분포를 나타냅니다 .xA
- 0≤τ≤1 은 정밀도 임계 값을 지정합니다. 최소한 의 로컬 충실도를 달성하는 규칙 만 유효한 결과로 간주됩니다.τ
공식적인 설명은 위협적 일 수 있으며 다음과 같이 말로 표현할 수 있습니다.
인스턴스 주어 를 설명하기 위해, 규칙 또는 앵커 가 적용되도록 발견 될 행 에 대해 동일한 수준의 동안 취득 동일한 가 적용될 수 있는 의 이웃 중 적어도 의 일부에 대해 예측됩니다 .
규칙의 정밀도 는 제공된 기계 학습 모델 (표시기 함수 로 표시됨)을 사용하여 이웃 또는 섭동 ( ) 을 평가 한 결과 입니다. ).xAxxτxADx(z|A)1f(x)=f(z)
앵커 찾기
앵커의 수학적 설명이 명확하고 간단 해 보일 수 있지만 특정 규칙을 구성하는 것은 불가능합니다.
이 평가 필요 모두 연속 또는 큰 입력에 불가능 공백. 따라서 저자 는 확률 적 정의를 생성하기 위해 매개 변수 를 도입 할 것을 제안합니다 .
이렇게하면 정밀도에 대한 통계적 신뢰가있을 때까지 샘플이 그려집니다.
확률 적 정의는 다음과 같습니다.1f(x)=f(z)z∈Dx(⋅|A)0≤δ≤1
P(prec(A)≥τ)≥1−δwithprec(A)=EDx(z|A)[1f(x)=f(z)]
이전의 두 정의는 적용 범위 개념에 의해 결합되고 확장됩니다.
그 이론적 근거는 모델 입력 공간의 많은 부분에 적용되는 규칙을 찾는 것으로 구성됩니다.
커버리지는 공식적으로 앵커의 이웃에 적용 할 확률, 즉 섭동 공간으로 정의됩니다.
cov(A)=ED(z)[A(z)]
이 요소를 포함하면 적용 범위 최대화를 고려한 앵커의 최종 정의로 이어집니다.
maxAs.t.P(prec(A)≥τ)≥1−δcov(A)
따라서 절차는 모든 적격 한 규칙 (확률 적 정의에 따라 정밀도 임계 값을 충족하는 모든 규칙) 중에서 가장 높은 적용 범위를 갖는 규칙을 위해 노력합니다.
이러한 규칙은 모델의 더 큰 부분을 설명하므로 더 중요하다고 생각됩니다.
술어가 많은 규칙은 술어가 적은 규칙보다 정밀도가 더 높은 경향이 있습니다. 특히 의 모든 기능을 수정하는 규칙 은 평가 된 이웃을 동일한 인스턴스로 줄입니다.
따라서 모델은 모든 이웃을 동일하게 분류하고 규칙의 정밀도는 입니다.
동시에 많은 기능을 수정하는 규칙은 지나치게 구체적이며 일부 인스턴스에만 적용됩니다.
따라서 정밀도와 적용 범위 사이 에는 상충 관계가 있습니다 .x1
앵커 접근 방식은 아래 그림과 같이 네 가지 주요 구성 요소를 사용하여 설명을 찾습니다.
후보 생성 : 새로운 설명 후보를 생성합니다.
첫 번째 라운드에서 기능 당 하나의 후보 가 생성되고 가능한 섭동의 각 값을 수정합니다.
다른 모든 라운드에서 이전 라운드의 가장 좋은 후보는 아직 포함되지 않은 하나의 기능 술어에 의해 확장됩니다.x
최우수 후보자 식별 : 어떤 규칙이 를 가장 잘 설명하는지에 따라 후보 규칙을 비교합니다 .
이를 위해 모델을 호출하여 현재 관찰 된 규칙과 일치하는 섭동을 평가합니다.
그러나 이러한 호출은 계산 오버 헤드를 제한하기 위해 최소화되어야합니다.
이것이이 구성 요소의 핵심에 순수 탐사 Multi-Armed-Bandit ( MAB ; KL-LUCB 41x, 정확하게). MAB는 순차 선택을 사용하여 다양한 전략 (슬롯 머신과 유사하게 팔이라고 함)을 효율적으로 탐색하고 활용하는 데 사용됩니다.
주어진 설정에서 각 후보 규칙은 당길 수있는 팔로 보여야합니다.
끌어 올 때마다 각 인접 항목이 평가되어 후보 규칙의 보상 (앵커의 경우 정밀도)에 대한 더 많은 정보를 얻습니다.
따라서 정밀도는 규칙이 설명 할 인스턴스를 얼마나 잘 설명 하는지를 나타냅니다.
후보 정밀도 검증 : 후보가 임계 값을 초과한다는 통계적 신뢰가없는 경우 더 많은 샘플을 가져옵니다 .τ
수정 된 빔 검색 : 위의 모든 구성 요소는 그래프 검색 알고리즘과 폭 우선 알고리즘의 변형 인 빔 검색으로 조합됩니다.
각 라운드 의 최고의 후보를 다음 라운드로 전달합니다 ( 는 Beam Width 라고 함 ).
이러한 최상의 규칙은 새 규칙을 만드는 데 사용됩니다.
빔 검색은 최대 라운드를 수행합니다. 각 피쳐는 규칙에 최대 한 번만 포함될 수 있기 때문입니다.
따라서 모든 라운드에서 , 정확히 술어를 가진 후보를 생성 하고 그 중에서 가장 좋은 B를 선택합니다.
따라서 설정하면BBBfeatureCount(x)iiB높으면 알고리즘이 로컬 최적화를 피할 가능성이 높습니다.
결과적으로 이것은 많은 수의 모델 호출을 필요로하므로 계산 부하가 증가합니다.
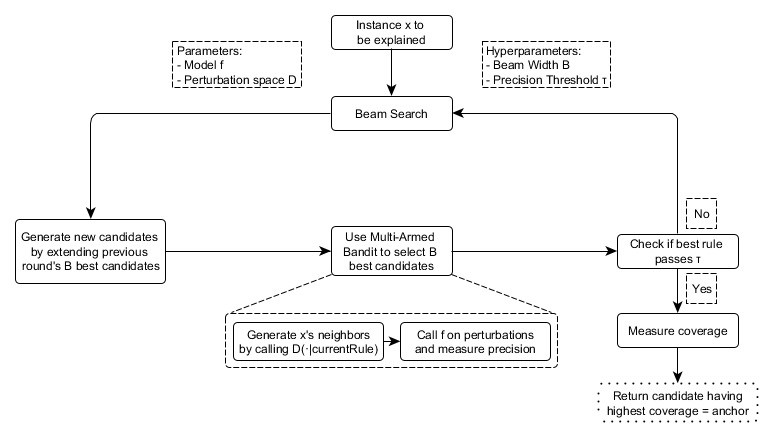
그림 5.38 : 앵커 알고리즘의 구성 요소 및 상호 관계 (단순화)
이 접근 방식은 시스템이 인스턴스를 분류 한 방식에 대해 통계적으로 건전한 정보를 효율적으로 도출 할 수있는 완벽한 방법입니다.
모델의 입력을 체계적으로 실험하고 각 출력을 관찰하여 결론을 내립니다.
모델에 대한 호출 수를 줄이기 위해 잘 확립되고 연구 된 기계 학습 방법 (MAB)에 의존합니다.
결과적으로 알고리즘의 실행 시간이 크게 감소합니다.
복잡성과 런타임
앵커 접근 방식의 점근 적 런타임 동작을 알면 특정 문제에서 얼마나 잘 수행 될 것으로 예상되는지 평가하는 데 도움이됩니다.
하자 빔 폭 나타낸다 의 모든 기능의 수. 그런 다음 앵커 알고리즘은 다음을 따릅니다.Bp
O(B⋅p2+p2⋅OMAB[B⋅p,B])
이 경계는 통계적 신뢰도 와 같은 문제 독립적 인 하이퍼 파라미터에서 추상화됩니다 .
하이퍼 파라미터를 무시하면 경계의 복잡성을 줄이는 데 도움이됩니다 (자세한 내용은 원본 문서 참조).
MAB는 각 라운드에서 후보 중에서 최선을 추출하기 때문에 대부분의 MAB와 해당 런타임은 다른 매개 변수보다 인수를 더 많이 곱합니다 .
BB⋅pp2
따라서 알고리즘의 효율성은 기능이 풍부한 문제로 인해 감소합니다.
테이블 형식 데이터 예
테이블 형식 데이터는 테이블로 표시되는 구조화 된 데이터로, 열은 기능 및 행 인스턴스를 구현합니다.
예를 들어 자전거 대여 데이터 를 사용하여 선택한 인스턴스에 대한 ML 예측을 설명하는 앵커 접근 방식의 잠재력을 보여줍니다.
이를 위해 회귀를 분류 문제로 전환하고 랜덤 포레스트를 블랙 박스 모델로 훈련합니다.
대여 자전거 대수가 추세선 위인지 아래인지 구분하는 것입니다.
앵커 설명을 작성하기 전에 섭동 함수를 정의해야합니다.
이를위한 쉬운 방법은 예를 들어 훈련 데이터에서 샘플링하여 구축 할 수있는 표 형식 설명 사례에 대해 직관적 인 기본 섭동 공간을 사용하는 것입니다.
인스턴스를 섭동 할 때이 기본 접근 방식은 앵커의 술어가 적용되는 기능의 값을 유지하면서 고정되지 않은 기능을 지정된 확률로 무작위로 샘플링 된 다른 인스턴스에서 가져온 값으로 대체합니다.
이 프로세스는 설명 된 것과 유사하지만 다른 임의의 인스턴스에서 일부 값을 채택한 새 인스턴스를 생성합니다. 따라서 그들은 이웃과 비슷합니다.
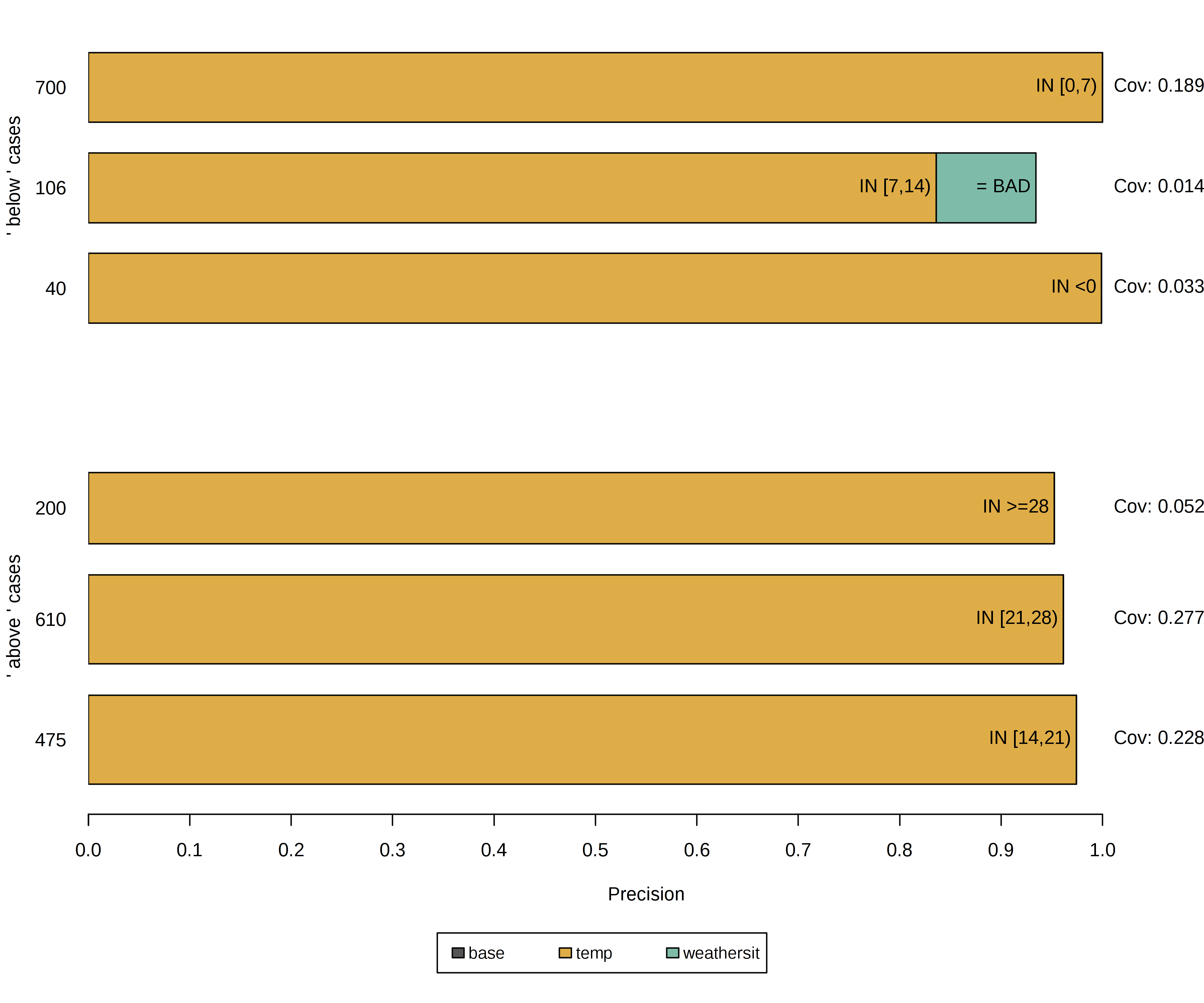
그림 5.39 : 자전거 대여 데이터 세트의 6 개 인스턴스를 설명하는 앵커. 각 행은 하나의 설명 또는 앵커를 나타내고 각 막대는 여기에 포함 된 기능 술어를 나타냅니다.
x 축은 규칙의 정밀도를 표시하고 막대의 두께는 해당 범위에 해당합니다. 'base'규칙에 술어가 없습니다.
이러한 앵커는 모델이 주로 예측을 위해 온도를 고려함을 보여줍니다.
결과는 본능적으로 해석 가능하며 모델의 예측에 가장 중요한 기능이 설명 된 각 인스턴스에 대해 표시됩니다.
앵커에는 몇 개의 술어 만 있으므로 추가적으로 높은 적용 범위를 가지므로 다른 경우에 적용됩니다.
위에 표시된 규칙은 로 생성되었습니다 .
따라서 평가 된 섭동이 최소한 의 정확도로 레이블을 충실하게 지원하는 앵커를 요청합니다 .
또한 숫자 특성의 표현력과 적용 가능성을 높이기 위해 이산화를 사용했습니다.τ=0.990%
이전의 모든 규칙은 모델이 몇 가지 기능을 기반으로 자신있게 결정하는 인스턴스에 대해 생성되었습니다.
그러나 다른 인스턴스는 더 많은 기능이 중요하기 때문에 모델에 따라 명확하게 분류되지 않습니다.
이러한 경우 앵커는 더 구체적이고 더 많은 기능을 구성하며 더 적은 인스턴스에 적용됩니다.
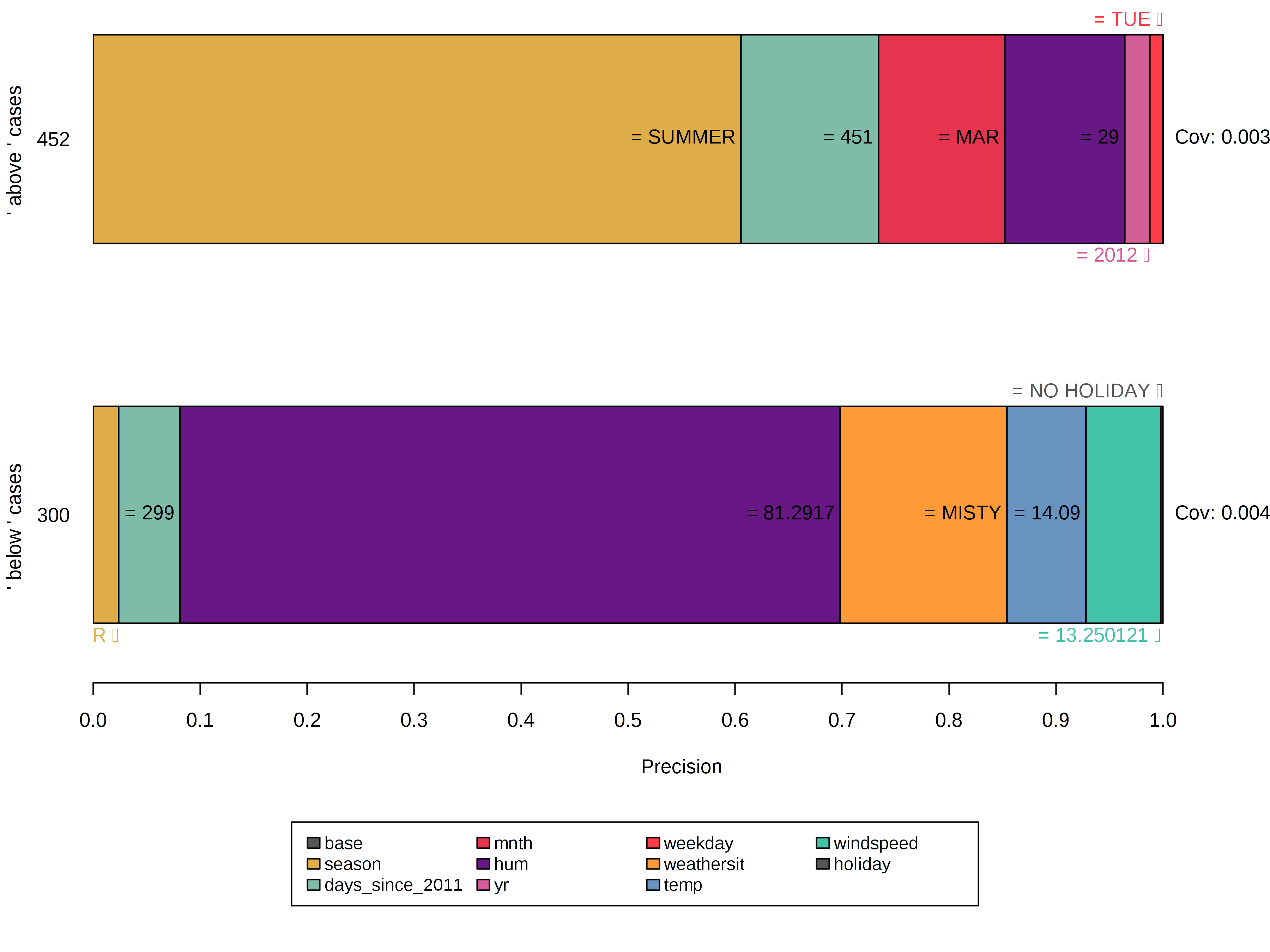
그림 5.40 : 결정 경계 근처의 인스턴스를 설명하면 더 많은 수의 기능 술어와 더 낮은 적용 범위로 구성된 특정 규칙으로 이어집니다. 또한 빈 규칙, 즉 기본 기능은 덜 중요합니다.
인스턴스가 휘발성 이웃에 있기 때문에 이는 결정 경계에 대한 신호로 해석 될 수 있습니다.
기본 섭동 공간을 선택하는 것이 편한 선택이지만 알고리즘에 큰 영향을 미치므로 편향된 결과로 이어질 수 있습니다.
예를 들어 열차 세트가 불균형 (각 클래스의 인스턴스 수가 같지 않음)이면 섭동 공간도 마찬가지입니다.
이 조건은 규칙 찾기 및 결과의 정밀도에 추가로 영향을줍니다.
자궁 경부암 데이터 세트는 앵커가 다음 상황 중 하나에 리드를 산법 적용이 상황의 훌륭한 예입니다 :
- 설명 인스턴스 레이블 건강한 생성 된 모든 이웃으로 평가로 수익률을 빈 규칙을 건강하게 .
- 암 으로 표시된 인스턴스에 대한 설명 은 지나치게 구체적입니다. 즉, 섭동 공간이 대부분 건강한 인스턴스의 값을 다루기 때문에 많은 기능 술어로 구성 됩니다.
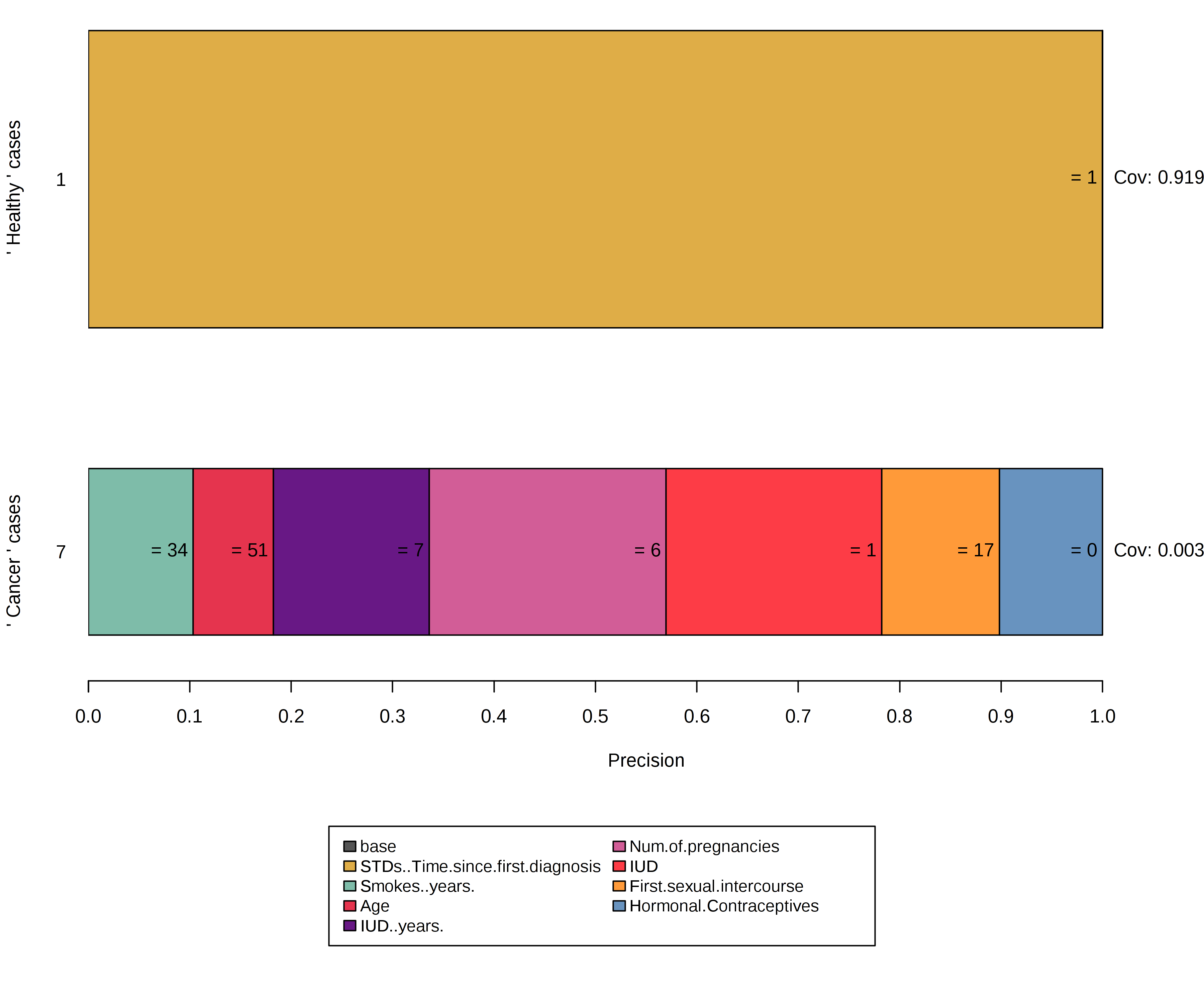
그림 5.41 : 불균형 섭동 공간 내에서 앵커를 구성하면 표현할 수없는 결과가 발생합니다.
이 결과는 원치 않을 수 있으며 여러 방법으로 접근 할 수 있습니다.
예를 들어, 불균형 데이터 세트 또는 정규 분포와 같이 다르게 샘플링하는 맞춤형 섭동 공간을 정의 할 수 있습니다.
그러나 이것은 부작용을 동반합니다.
샘플링 된 이웃이 대표적이지 않고 적용 범위를 변경합니다. 또는 MAB의 신뢰도 및 오류 매개 변수 값 수정할 수 있습니다.
이로 인해 MAB는 더 많은 샘플을 추출하여 궁극적으로 소수가 절대적인 용어로 더 자주 샘플링되도록합니다.δϵ
이 예에서는 대부분의 사례가 암 으로 분류 된 자궁 경부암 세트의 하위 집합을 사용합니다 .
그런 다음 그에 상응하는 섭동 공간을 생성하는 프레임 워크가 있습니다.
섭동은 이제 다양한 예측으로 이어질 가능성이 높으며 앵커 알고리즘은 중요한 특징을 식별 할 수 있습니다.
그러나 커버리지의 정의를 고려해야합니다.
이는 섭동 공간 내에서만 정의됩니다. 이전 예제에서는 섭동 공간의 기초로 기차 세트를 사용했습니다.
여기서는 하위 집합 만 사용하므로 높은 적용 범위가 반드시 전역 적으로 높은 규칙 중요성을 나타내는 것은 아닙니다.
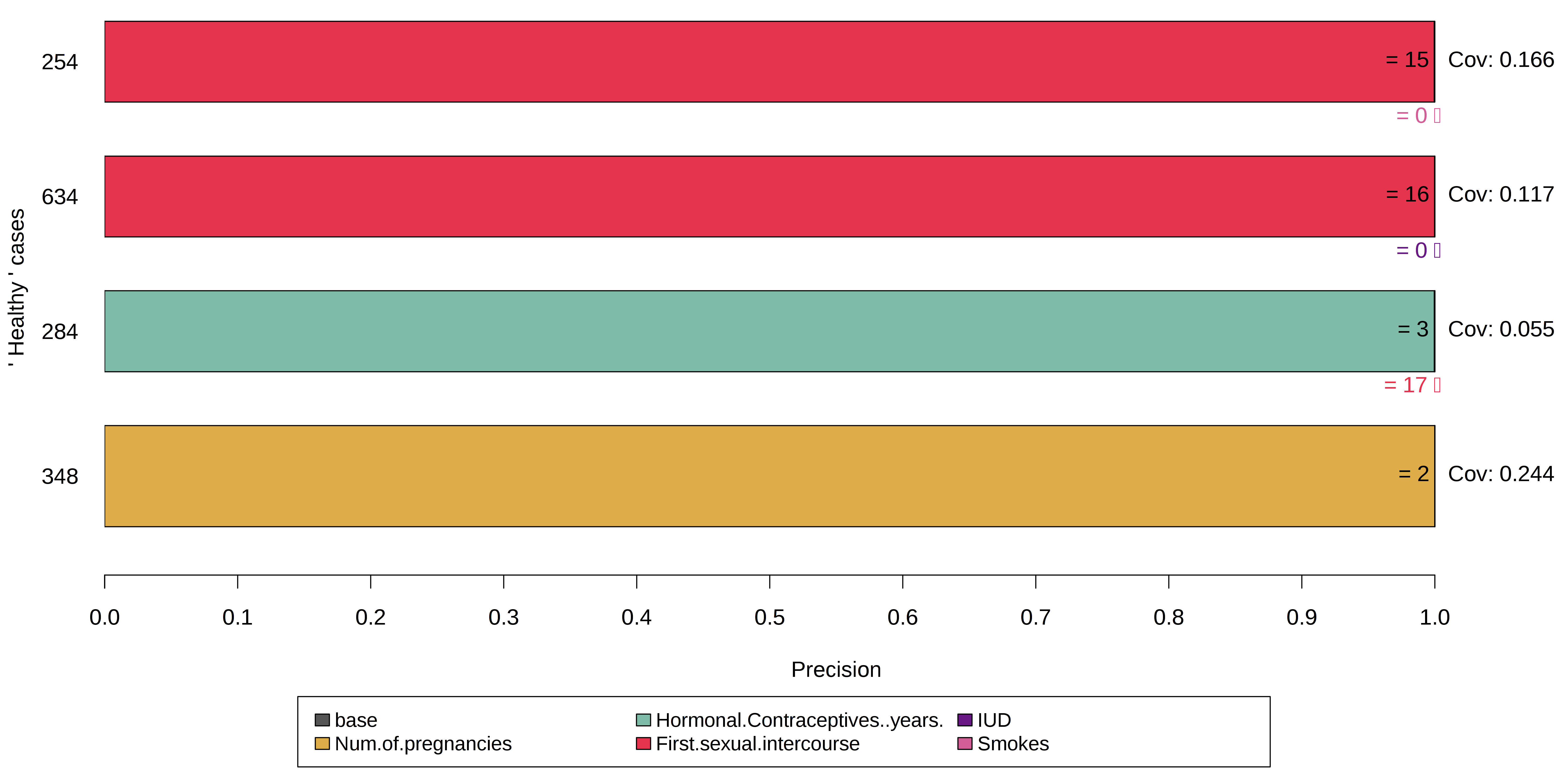
그림 5.42 : 앵커를 구성하기 전에 데이터 세트의 균형을 맞추면 소수의 경우 결정에 대한 모델의 추론이 표시됩니다.
장점
앵커 접근 방식은 LIME에 비해 여러 가지 이점을 제공합니다.
첫째, 규칙이 해석하기 쉽기 때문에 알고리즘의 출력이 이해하기 더 쉽습니다 (비전문가에게도 해당).
또한 앵커는 하위 집합이 가능 하며 커버리지 개념을 포함하여 중요도를 표시합니다.
둘째, 앵커 접근 방식 은 모델 예측이 인스턴스의 이웃에서 비선형이거나 복잡한 경우 작동합니다 .
접근 방식이 대리 모델을 맞추는 대신 강화 학습 기술을 배포하므로 모델을 과소 적합 할 가능성이 적습니다.
그 외에도 알고리즘은 모델에 구애받지 않으므로 모든 모델에 적용 할 수 있습니다.
또한 배치 샘플링 (예 : BatchSAR)을 지원하는 MAB를 사용하여 병렬화 할 수 있으므로 매우 효율적 입니다.
단점
알고리즘 은 대부분의 섭동 기반 설명자처럼 구성 가능성 이 높고 영향력있는 설정으로 인해 어려움을 겪습니다 .
의미있는 결과를 생성하기 위해 빔 폭 또는 정밀도 임계 값과 같은 하이퍼 파라미터를 조정해야 할뿐만 아니라 섭동 함수가 하나의 도메인 / 사용 사례에 대해 명시 적으로 설계되어야합니다.
표 형식 데이터가 어떻게 교란되는지 생각하고 이미지 데이터에 동일한 개념을 적용하는 방법을 생각하십시오 (힌트 : 적용 할 수 없음). 운 좋게도 기본 접근 방식은 일부 도메인 (예 : 표 형식)에서 사용되어 초기 설명 설정을 용이하게 할 수 있습니다.
또한 결과가 너무 구체적이고 적용 범위가 낮으며 모델 이해에 기여하지 않기 때문에 많은 시나리오에서 이산화 가 필요합니다 .
이산화가 도움이 될 수 있지만 부주의하게 사용하면 결정 경계가 흐려져 정반대의 효과가 발생할 수도 있습니다.
최상의 이산화 기술이 없기 때문에 사용자는 데이터를 이산화하는 방법을 결정하기 전에 데이터를 알고 있어야 나쁜 결과를 얻지 못합니다.
앵커를 구성하려면 모든 섭동 기반 설명자처럼 ML 모델에 대한 많은 호출이 필요합니다 .
알고리즘은 MAB를 배포하여 호출 수를 최소화하지만 런타임은 여전히 모델의 성능에 크게 의존하므로 매우 가변적입니다.
마지막으로 커버리지 의 개념은 일부 도메인에서 정의되지 않습니다 .
예를 들어 한 이미지의 슈퍼 픽셀이 다른 이미지의 슈퍼 픽셀과 어떻게 비교되는지에 대한 분명하거나 보편적 인 정의가 없습니다.
소프트웨어 및 대안
현재 사용 가능한 두 가지 구현이 있습니다.
앵커, Python 패키지 ( Alibi에 의해 통합됨 ) 및 Java 구현 입니다.
전자는 앵커 알고리즘의 작성자 참조이며 후자는 이 장의 예제에 사용 된 anchors 라고하는 R 인터페이스와 함께 제공되는 고성능 구현입니다 .
현재 앵커는 표 형식 데이터 만 지원합니다.
그러나 이론적으로 앵커는 모든 도메인 또는 데이터 유형에 대해 구성 될 수 있습니다.
- Marco Tulio Ribeiro, Sameer Singh, Carlos Guestrin. "앵커 : 고정밀 모델에 구애받지 않는 설명." AAAI 인공 지능 컨퍼런스 (AAAI), 2018 ↩
- Emilie Kaufmann과 Shivaram Kalyanakrishnan. “산적 하위 집합 선택의 정보 복잡성”. Machine Learning Research (2013)의 회보.
Shapley 값
인스턴스의 각 특성 값이 예측이 지불금 인 게임에서 "플레이어"라고 가정하여 예측을 설명 할 수 있습니다.
연합 게임 이론의 방법 인 Shapley 값은 기능간에 "지급금"을 공정하게 분배하는 방법을 알려줍니다.
SHAP 및 Shapley 가치에 대한 심층 실습 과정에 관심이 있으십니까? 로 향할 샤플리 코스 페이지 와 과정을 사용할되면 알림을받을.
일반 아이디어
다음 시나리오를 가정하십시오.
아파트 가격을 예측하기 위해 기계 학습 모델을 학습했습니다.
특정 아파트의 경우 300,000 유로가 예상되며이 예측을 설명해야합니다.
이 아파트의 면적은 50m2이고 2 층에 위치해 있으며 근처에 공원이 있으며 고양이는 금지되어 있습니다.

그림 5.43하십시오 50m의 예상 가격 이 가까운 공원 고양이 금지와 2 층 아파트는 € 300,000이다.
우리의 목표는 이러한 각 특성 값이 예측에 어떻게 기여했는지 설명하는 것입니다.
모든 아파트의 평균 예측은 € 310,000입니다.
평균 예측과 비교하여 각 특성 값이 예측에 얼마나 기여 했습니까?
선형 회귀 모델의 경우 답은 간단합니다.
각 특성의 효과는 특성의 가중치에 특성 값을 곱한 것입니다.
이것은 모델의 선형성 때문에 만 작동합니다.
더 복잡한 모델의 경우 다른 솔루션이 필요합니다.
예를 들어, LIME 은 효과를 추정하기 위해 지역 모델을 제안합니다.
또 다른 해결책은 협동 게임 이론에서 비롯됩니다.
Shapley (1953) 가 만든 Shapley 가치 는 총 지불금에 대한 기여도에 따라 플레이어에게 지불금을 할당하는 방법입니다.
플레이어는 연합에서 협력하고이 협력에서 일정한 이익을 얻습니다.
플레이어? 경기? 지불금? 기계 학습 예측 및 해석 가능성과의 연관성은 무엇입니까? "게임"은 데이터 세트의 단일 인스턴스에 대한 예측 작업입니다.
'이득'은이 인스턴스의 실제 예측에서 모든 인스턴스의 평균 예측을 뺀 값입니다.
"플레이어"는 이득을 받기 위해 협력하는 인스턴스의 특성 값입니다 (= 특정 값 예측).
우리 아파트의 예에서, 특징 값은 park-nearby, cat-banned, area-50및 floor-2nd€ 300,000의 예측을 달성하기 위해 함께 일했다.
우리의 목표는 실제 예측 (€ 300,000)과 평균 예측 (€ 310,000)의 차이를 설명하는 것입니다 :-€ 10,000의 차이.
대답은 다음과 같을 수 있습니다.
park-nearby기부 된 € 30,000; area-50€ 10,000 기부; floor-2nd기부 € 0; cat-banned기부-€ 50,000. 기여금의 합은-€ 10,000이며, 최종 예측에서 평균 예상 아파트 가격을 뺀 값입니다.
한 기능에 대한 Shapley 값을 어떻게 계산합니까?
Shapley 값은 가능한 모든 연합에서 기능 값의 평균 한계 기여도입니다. 이제 모두 명확합니까?
다음 그림에서는 및 cat-banned의 연합에 추가 될 때 특성 값 의 기여도를 평가합니다 .
우리 는 데이터에서 무작위로 다른 아파트를 그리고 바닥 피처에 대한 값을 사용하여 , 그리고 연합에있는 것만 시뮬레이션 합니다.
값 은 무작위로 그려진으로 대체되었습니다 .
그런 다음이 조합 (€ 310,000)으로 아파트 가격을 예측합니다.
두 번째 단계에서는 무작위로 그려진 아파트에서 고양이 허용 / 금지 기능의 무작위 값으로 대체하여 연합에서 제거 합니다.
예에서는 였지만 다시 그럴 수도 있습니다 .
우리의 연합의 아파트 가격을 예측 하고park-nearbyarea-50park-nearbycat-bannedarea-50floor-2ndfloor-1stcat-bannedcat-allowedcat-bannedpark-nearbyarea-50(€ 320,000). 기부금 cat-banned은 € 310,000-€ 320,000 =-€ 10,000입니다.
이 추정치는 고양이 및 바닥 특성 값에 대한 "기증자"역할을하는 무작위로 그려진 아파트의 값에 따라 다릅니다.
이 샘플링 단계를 반복하고 기여도를 평균화하면 더 나은 추정치를 얻을 수 있습니다.

그림 5.44 : 및 cat-banned의 연합에 추가 될 때 예측에 대한 기여도를 추정하기위한 하나의 샘플 반복 . park-nearbyarea-50
가능한 모든 연합에 대해이 계산을 반복합니다.
Shapley 값은 가능한 모든 연합에 대한 모든 한계 기여도의 평균입니다.
계산 시간은 기능 수에 따라 기하 급수적으로 증가합니다.
계산 시간을 관리 가능한 상태로 유지하기위한 한 가지 솔루션은 가능한 연합의 몇 가지 샘플에 대해서만 기여도를 계산하는 것입니다.
다음 그림은에 대한 Shapley 값을 결정하는 데 필요한 특성 값의 모든 연합을 보여줍니다
cat-banned.
첫 번째 행은 특성 값이없는 연합을 보여줍니다.
두 번째, 세 번째 및 네 번째 행은 "|"로 구분 된 연합 크기가 증가함에 따라 서로 다른 연합을 표시합니다.
대체로 다음과 같은 연합이 가능합니다.
- No feature values
- park-nearby
- area-50
- floor-2nd
- park-nearby+area-50
- park-nearby+floor-2nd
- area-50+floor-2nd
- park-nearby+ area-50+ floor-2nd.
이러한 각 연합에 대해 기능 값이 있거나없는 예상 아파트 가격을 계산 cat-banned하고 차이를 가져서 한계 기여도를 얻습니다.
Shapley 값은 한계 기여도의 (가중치) 평균입니다.
기계 학습 모델에서 예측을 얻기 위해 연합에없는 특성의 특성 값을 아파트 데이터 세트의 임의 특성 값으로 대체합니다.

그림 5.45 : cat-banned기능 값 의 정확한 Shapley 값을 계산하는 데 필요한 모든 8 개의 연합 .
모든 특성 값에 대한 Shapley 값을 추정하면 특성 값간에 예측의 전체 분포 (평균 마이너스)를 얻습니다.
예 및 해석
특성 값 j에 대한 Shapley 값의 해석은 다음과 같습니다.
기여한 j 번째 특성의 값 ϕj 데이터 세트에 대한 평균 예측과 비교 한이 특정 인스턴스의 예측에.
Shapley 값은 분류 (확률을 다루는 경우)와 회귀 모두에 적용됩니다.
Shapley 값을 사용하여 자궁 경부암을 예측하는 무작위 숲 모델의 예측을 분석합니다 .

그림 5.46 : 자궁 경부암 데이터 세트에서 여성에 대한 Shapley 값. 0.57의 예측에서이 여성의 암 확률은 평균 예측 0.03보다 0.54 높습니다.
진단 된 성병의 수는 확률을 가장 높였습니다.
기여도의 합계는 실제 예측과 평균 예측 (0.54)의 차이를 산출합니다.
를 들어 자전거 대여 데이터 세트 , 우리는 또한 하루 동안 주어진 날씨와 일정 정보를 임대 자전거의 수를 예측하는 임의의 숲을 훈련. 특정 날짜의 랜덤 포레스트 예측에 대한 설명 :

그림 5.47 : 285 일의 Shapley 값. 예상되는 2409 대의 자전거 대여시 오늘은 평균 예측 인 4518보다 -2108이 낮습니다.
날씨 상황과 습도가 가장 부정적인 영향을 미쳤습니다.
이날 기온은 긍정적 인 영향을 미쳤습니다.
Shapley 값의 합은 실제와 평균 예측의 차이를 산출합니다 (-2108).
Shapley 값을 올바르게 해석해야합니다.
Shapley 값은 서로 다른 연합에서 예측에 대한 특성 값의 평균 기여도입니다.
Shapley 값은 모델에서 기능을 제거 할 때 예측의 차이가 아닙니다.
Shapley의 세부 가치
이 섹션에서는 호기심 많은 독자를위한 Shapley 값의 정의 및 계산에 대해 자세히 설명합니다.
기술적 세부 사항에 관심이 없으면이 섹션을 건너 뛰고 "장점 및 단점"으로 바로 이동하십시오.
우리는 각 특징이 데이터 포인트의 예측에 어떤 영향을 미치는지에 관심이 있습니다.
선형 모델에서는 개별 효과를 쉽게 계산할 수 있습니다.
다음은 하나의 데이터 인스턴스에 대한 선형 모델 예측의 모습입니다.
f^(x)=β0+β1x1+…+βpxp
여기서 x는 기여도를 계산하려는 인스턴스입니다.
마다xjj = 1, ..., p 인 특성 값입니다. 그만큼βj 특징 j에 해당하는 가중치입니다.
기여 ϕj 예측에서 j 번째 특성의 f^(x) is :
ϕj(f^)=βjxj−E(βjXj)=βjxj−βjE(Xj)
어디 E(βjXj)특징 j에 대한 평균 효과 추정치입니다.
기여도는 기능 효과에서 평균 효과를 뺀 차이입니다.
좋은! 이제 각 기능이 예측에 얼마나 기여했는지 알 수 있습니다.
한 인스턴스에 대한 모든 기능 기여를 합산하면 결과는 다음과 같습니다.
∑제이=1피ϕ제이(에프^)=∑제이=1피(β제이엑스제이−이자형(β제이엑스제이))=(β0+∑제이=1피β제이엑스제이)−(β0+∑제이=1피이자형(β제이엑스제이))=에프^(엑스)−이자형(에프^(엑스))
이것은 데이터 포인트 x에 대한 예측 값에서 평균 예측 값을 뺀 값입니다.
기능 기여도는 부정적 일 수 있습니다.
모든 유형의 모델에 대해 동일한 작업을 수행 할 수 있습니까? 이것을 모델에 구애받지 않는 도구로 사용하면 좋을 것입니다.
일반적으로 다른 모델 유형에는 유사한 가중치가 없기 때문에 다른 솔루션이 필요합니다.
도움은 예상치 못한 곳에서 나옵니다 : 협동 게임 이론. Shapley 값은 모든 기계 학습 모델의 단일 예측에 대한 기능 기여도를 계산하기위한 솔루션입니다.
5.9.3.1 Shapley 가치
Shapley 값은 S에서 플레이어의 값 함수 val을 통해 정의됩니다.
기능 값의 Shapley 값은 가능한 모든 기능 값 조합에 대해 가중치가 적용되고 합산 된 지불에 대한 기여도입니다.
ϕj(val)=∑S⊆{x1,…,xp}∖{xj}|S|!(p−|S|−1)!p!(val(S∪{xj})−val(S))
여기서 S는 모델에 사용 된 특성의 하위 집합이고 x는 설명 할 인스턴스의 특성 값으로 구성된 벡터이고 p는 특성 수입니다. valx(S) 세트 S에 포함되지 않은 특성보다 소외된 세트 S의 특성 값에 대한 예측입니다.
valx(S)=∫f^(x1,…,xp)dPx∉S−EX(f^(X))
실제로 S가 포함되지 않은 각 기능에 대해 여러 통합을 수행합니다.
구체적인 예 : 기계 학습 모델은 4 개의 기능 x1, x2, x3 및 x4와 함께 작동하며 특성 값 x1 및 x3으로 구성된 연합 S에 대한 예측을 평가합니다.
Vㅏ엘엑스(에스)=Vㅏ엘엑스({엑스1,엑스삼})=∫아르 자형∫아르 자형에프^(엑스1,엑스2,엑스삼,엑스4)디피엑스2엑스4−이자형엑스(에프^(엑스))
이것은 선형 모델의 기능 기여와 유사합니다!
"값"이라는 단어가 많이 사용되어 혼동하지 마십시오.
기능 값은 기능 및 인스턴스의 숫자 또는 범주 값입니다.
Shapley 값은 예측에 대한 기능 기여도입니다.
가치 함수는 플레이어 연합에 대한 지불 함수입니다 (특성 값).
Shapley 값은 효율성 , 대칭 , 더미 및 가산 성 속성을 충족하는 유일한 귀속 방법 이며 , 함께 공정한 지불의 정의로 간주 될 수 있습니다.
효율성 기능 기여도는 x와 평균에 대한 예측의 차이에 더해져야합니다.
∑제이=1피ϕ제이=에프^(엑스)−이자형엑스(에프^(엑스))
대칭 두 특성 값 j 및 k의 기여도는 가능한 모든 연합에 동일하게 기여하는 경우 동일해야합니다. 만약
Vㅏ엘(에스∪{엑스제이})=Vㅏ엘(에스∪{엑스케이})
모든
에스⊆{엑스1,…,엑스피}∖{엑스제이,엑스케이}
그때
ϕ제이=ϕ케이
더미 추가 된 특성 값의 연합에 관계없이 예측 값을 변경하지 않는 특성 j는 Shapley 값이 0이어야합니다.
val(S∪{xj})=val(S)
모든
S⊆{x1,…,xp}
그때
ϕj=0
가산 성 조합 된 지불금이있는 게임의 경우 val + val + 각 Shapley 값은 다음과 같습니다.
ϕj+ϕj+
임의의 포리스트를 훈련했다고 가정합니다.
이는 예측이 많은 의사 결정 트리의 평균임을 의미합니다.
Additivity 속성은 기능 값에 대해 각 트리에 대한 Shapley 값을 개별적으로 계산하고 평균을 내고 임의 포리스트의 기능 값에 대한 Shapley 값을 가져올 수 있음을 보장합니다.
직관
Shapley 값을 이해하는 직관적 인 방법은 다음 그림입니다.
기능 값이 무작위 순서로 방에 들어갑니다.
방의 모든 특성 값이 게임에 참여합니다 (= 예측에 기여). 특성 값의 Shapley 값은 특성 값이 결합 될 때 이미 회의실에있는 연합이받는 예측의 평균 변화입니다.
Shapley 값 추정
정확한 Shapley 값을 계산하려면 모든 가능한 특성 값 연합 (세트)을 j 번째 특성을 포함하거나 포함하지 않고 평가해야합니다.
몇 가지 이상의 기능의 경우, 더 많은 기능이 추가 될수록 가능한 연합 수가 기하 급수적으로 증가하므로이 문제에 대한 정확한 솔루션이 문제가됩니다.
Strumbelj et al. (2014) 은 Monte-Carlo 샘플링을 사용한 근사치를 제안합니다.
ϕ^j=1M∑m=1M(f^(x+jm)−f^(x−jm))
어디 f^(x+jm)는 x에 대한 예측이지만, 특성 j의 각 값을 제외하고 임의의 데이터 포인트 z의 특성 값으로 대체 된 임의의 특성 값을 사용합니다.
x- 벡터x−jm 거의 동일하다 x+jm,하지만 값 xjm또한 샘플링 된 z에서 가져옵니다.
이 M 개의 새로운 인스턴스 각각은 두 개의 인스턴스로 구성된 일종의 "Frankenstein Monster"입니다.
단일 특성 값에 대한 대략적인 Shapley 추정값 :
- 출력 : j 번째 특성 값에 대한 Shapley 값
- 필수 : 반복 횟수 M, 관심 인스턴스 x, 특성 인덱스 j, 데이터 행렬 X 및 기계 학습 모델 f
- 모든 m = 1, ..., M :
- 데이터 행렬 X에서 임의의 인스턴스 z를 그립니다.
- 특성 값의 임의 순열을 선택합니다.
- 주문 인스턴스 x : xo=(x(1),…,x(j),…,x(p))
- 주문 인스턴스 z : zo=(z(1),…,z(j),…,z(p))
- 두 개의 새 인스턴스 생성
- 기능 j 사용 : x+j=(x(1),…,x(j−1),x(j),z(j+1),…,z(p))
- 기능 j가없는 경우 : x−j=(x(1),…,x(j−1),z(j),z(j+1),…,z(p))
- 한계 기여도 계산 : ϕjm=f^(x+j)−f^(x−j)
- Shapley 값을 평균으로 계산합니다. ϕj(x)=1M∑m=1Mϕjm
먼저 관심 인스턴스 x, 특징 j 및 반복 횟수 M을 선택합니다.
각 반복에 대해 데이터에서 임의의 인스턴스 z가 선택되고 특징의 임의 순서가 생성됩니다.
관심 인스턴스 x와 샘플 z의 값을 결합하여 두 개의 새로운 인스턴스가 생성됩니다.
인스턴스x+j은 관심 인스턴스이지만 특성 j 이후 순서의 모든 값은 샘플 z의 특성 값으로 대체됩니다.
인스턴스x−j 와 같다 x+j, 그러나 추가로 특징 j가 샘플 z의 특징 j 값으로 대체되었습니다.
블랙 박스와의 예측 차이가 계산됩니다.
ϕjm=f^(x+jm)−f^(x−jm)
이러한 모든 차이는 평균이며 결과는 다음과 같습니다.
ϕ제이(엑스)=1미디엄∑미디엄=1미디엄ϕ제이미디엄
평균화는 X의 확률 분포에 따라 샘플의 무게를 암시 적으로 측정합니다.
모든 Shapley 값을 얻으려면 각 기능에 대해 절차를 반복해야합니다.
장점
예측과 평균 예측의 차이 는 인스턴스의 특성 값인 Shapley 값의 효율성 속성에 상당히 분산되어 있습니다.
이 속성은 Shapley 값을 LIME 와 같은 다른 메서드와 구별합니다 .
LIME은 예측이 기능간에 공정하게 배포된다는 것을 보장하지 않습니다.
Shapley 값은 전체 설명을 제공하는 유일한 방법 일 수 있습니다.
EU의 "설명에 대한 권리"와 같이 법률이 설명 가능성을 요구하는 상황에서 Shapley 가치는 견고한 이론을 기반으로하고 효과를 공정하게 분배하기 때문에 법적으로 준수하는 유일한 방법 일 수 있습니다.
나는 변호사가 아니기 때문에 이것은 요구 사항에 대한 나의 직감만을 반영합니다.
Shapley 값은 대조적 인 설명을 허용 합니다.
예측을 전체 데이터 세트의 평균 예측과 비교하는 대신 하위 집합 또는 단일 데이터 포인트와 비교할 수 있습니다.
이 대비도 LIME과 같은 지역 모델에는없는 것입니다.
Shapley 값은 확실한 이론을 가진 유일한 설명 방법입니다 .
공리 (효율성, 대칭성, 더미, 가산 성)는 설명에 합리적인 기초를 제공합니다.
LIME과 같은 방법은 기계 학습 모델의 선형 동작을 로컬에서 가정하지만 이것이 작동해야하는 이유에 대한 이론은 없습니다.
그것은하는 마음 - 불고 게임으로 예측 설명 특징 값에 의해 연주합니다.
단점
Shapley 값에는 많은 컴퓨팅 시간이 필요 합니다 .
실제 문제의 99.9 %에서 근사 솔루션 만 가능합니다.
Shapley 값의 정확한 계산은 2k 가 있기 때문에 계산 비용이 많이 듭니다.
특성 값의 가능한 연합과 특성의 "부재"는 임의의 인스턴스를 그려서 시뮬레이션해야하며, 이는 Shapley 값 추정의 추정에 대한 분산을 증가시킵니다.
연합의 지수 적 수는 연합을 샘플링하고 반복 횟수 M을 제한하여 처리됩니다.
M을 줄이면 계산 시간이 줄어들지 만 Shapley 값의 분산이 증가합니다.
반복 횟수 M에 대한 좋은 경험 법칙이 없습니다.
M은 Shapley 값을 정확하게 추정 할 수있을만큼 커야하지만 적절한 시간 내에 계산을 완료 할 수있을만큼 작아야합니다.
Chernoff 경계를 기반으로 M을 선택하는 것이 가능해야하지만 기계 학습 예측을 위해 Shapley 값에 대해이를 수행하는 것에 대한 논문을 보지 못했습니다.
Shapley 값 은 잘못 해석 될 수 있습니다 .
특성 값의 Shapley 값은 모델 학습에서 특성을 제거한 후 예측 된 값의 차이가 아닙니다.
Shapley 값의 해석은 다음과 같습니다.
현재 특성 값 집합이 주어지면 실제 예측과 평균 예측 간의 차이에 대한 특성 값의 기여는 추정 된 Shapley 값입니다.
희소 한 설명 (특징이 거의없는 설명)을 찾는 경우 Shapley 값은 잘못된 설명 방법입니다.
Shapley 값 방법으로 작성된 설명은 항상 모든 기능을 사용합니다 .
인간은 LIME에서 나오는 것과 같은 선택적인 설명을 선호합니다.
비전문가가 다루어야하는 설명에는 LIME이 더 나은 선택 일 수 있습니다.
또 다른 솔루션은 Lundberg와 Lee (2016) 44 가 소개 한 SHAP 로, Shapley 값을 기반으로하지만 몇 가지 기능으로 설명을 제공 할 수도 있습니다.
Shapley 값은 특성별로 간단한 값을 반환하지만 LIME과 같은 예측 모델 은 없습니다 .
즉, "연간 300 유로를 더 벌면 신용 점수가 5 점 올라갈 것입니다."와 같이 입력 변경에 대한 예측 변경에 대한 진술을하는 데 사용할 수 없습니다.
또 다른 단점은 새 데이터 인스턴스에 대한 Shapley 값을 계산하려는 경우 데이터에 액세스해야 한다는 것 입니다.
관심있는 인스턴스의 일부를 무작위로 그려진 데이터 인스턴스의 값으로 대체하기 위해 데이터가 필요하기 때문에 예측 함수에 액세스하는 것만으로는 충분하지 않습니다.
이는 실제 데이터 인스턴스처럼 보이지만 훈련 데이터의 실제 인스턴스가 아닌 데이터 인스턴스를 생성 할 수있는 경우에만 피할 수 있습니다.
다른 많은 순열 기반 해석 방법과 마찬가지로 Shapley 값 방법 은 비현실적인 데이터 인스턴스 를 포함 하는 문제가 있습니다.
기능이 상관 될 때. 연합에서 기능 값이 누락되었음을 시뮬레이션하기 위해 기능을 주 변화합니다.
이것은 기능의 한계 분포에서 값을 샘플링하여 달성됩니다.
기능이 독립적 인 한 괜찮습니다.
특성이 종속적이면이 인스턴스에 적합하지 않은 특성 값을 샘플링 할 수 있습니다.
그러나이를 사용하여 기능의 Shapley 값을 계산합니다.
한 가지 해결책은 상관 된 기능을 함께 퍼 뮤트하고 이들에 대해 하나의 상호 Shapley 값을 얻는 것입니다.
또 다른 적응은 조건부 샘플링입니다.
기능은 이미 팀에있는 기능에 대해 조건부로 샘플링됩니다.
조건부 샘플링이 비현실적인 데이터 포인트 문제를 해결하는 동안 새로운 문제가 도입되었습니다.
결과 값은 더 이상 게임의 Shapley 값이 아닙니다.
Sundararajan et.에 의해 발견 된 대칭 공리를 위반하기 때문에. al (2019)및 Janzing et. al (2020) .
소프트웨어 및 대안
Shapley 값은 R 용 iml및 fastshap 패키지 모두에서 구현됩니다 .
Shapley 값에 대한 대체 추정 방법 인 SHAP가 다음 장에 나와 있습니다.
breakDownR 패키지 에서 구현되는 또 다른 접근 방식은 breakDown이라고 합니다 .
BreakDown은 또한 예측에 대한 각 기능의 기여도를 보여 주지만 단계별로 계산합니다.
게임 비유를 다시 사용하겠습니다.
빈 팀으로 시작하여 예측에 가장 많이 기여할 특성 값을 추가하고 모든 특성 값이 추가 될 때까지 반복합니다.
각 특성 값이 기여하는 정도는 이미 "팀"에있는 각 특성 값에 따라 달라지며 이는 breakDown 메서드의 큰 단점입니다.
Shapley 값 방법보다 빠르며 상호 작용이없는 모델의 경우 결과는 동일합니다.
- Shapley, Lloyd S. "n 인 게임의 가치." 게임 이론에 대한 기여 2.28 (1953) : 307-317.
- Štrumbelj, Erik 및 Igor Kononenko. "기능 기여와 함께 예측 모델 및 개별 예측을 설명합니다."
- 지식 정보 시스템 41.3 (2014) : 647-665.
- Lundberg, Scott M., 이수인. "모델 예측 해석에 대한 통합 접근 방식." 신경 정보 처리 시스템의 발전. 2017.
- Sundararajan, Mukund 및 Amir Najmi. "모델 설명을위한 많은 Shapley 값." arXiv 사전 인쇄 arXiv : 1908.08474 (2019).
- Janzing, Dominik, Lenon Minorics 및 Patrick Blöbaum. "설명 가능한 AI의 기능 관련성 정량화 : 인과 적 문제." 인공 지능 및 통계에 관한 국제 회의. PMLR, 2020
- Staniak, Mateusz 및 Przemyslaw Biecek. "라이브 및 분석 패키지를 사용한 모델 예측에 대한 설명." arXiv 사전 인쇄 arXiv : 1804.01955 (2018).
#Shaple #모델 설명 #breakDown 메서드의 큰 단점 #라이브 #분석 패키지 #게임 비유 #기능의 기여도 #단계별로 계산 #조건부 샘플링 #비현실적인 데이터 #포인트 문제를 해결 #새로운 문제가 도입 #결과 값 #게임의 Shapley 값 #Sundararajan et #발견 된 대칭 공리를 위반 #al (2019) #Janzing et al (2020) #데이터 인스턴스 를 포함 하는 문제 #기능이 상관 #연합에서 기능 값이 누락 #시뮬레이션 #소프트웨어 #인스턴스x−j #추가로 특징 j #샘플 z의 특징 # j 값으로 대체 #블랙 박스 #Anchors #그래프검색 #알고리즘 #강화 학습 #기술을 활용
***~^0^~ 다른 youtu.be 영상보기,
아래 클릭 하시면 시청 하실수가 있읍니다,
https://www.youtube.com/channel/UCNCZRbUDsmBBKCau3SveIKg
youtu.be/IOzjiVnjFTQ
youtu.be/zc7-qFYKACM
영상을 재미있고 의미있게 보셨다면 ''구독 '좋아요',
그리고 '알림 설정'을 꼭 누르셔서 다음 영상도 함께 해주세요.
^^ 영상 구독 좋아요 누르시면 그 이익금 일부는 불우 이웃에 쓰여집니다ㅡ
많은 성원과 격려 부탁 드립니다,
구독 좋아요 알림설정은 무료입니다,
항상 응원해 주셔서 ~ ♡감사합니다.. -^0^-,,,.


